
AI From an Open Perspective
The burst of Artificial Intelligence (AI) onto the scene at the start of 2023 caught my interest along with everyone else. Over the course of my high tech career the sudden emergence of a new technology and the ensuing hype cycle has been a common occurrence. But AI was over the top - seemingly everywhere, affecting all endeavours, with a relentless hype cycle full of fears and hopes.
When a new technology like this takes off I like to get hands-on with it. So I began experimenting with Chat-GPT and DALL-E. I was impressed with the clear, concise, and well written answers ChatGPT generated. It seemed thoughtful, well spoken, almost human. It came across as definitive and seemingly authoritative. However, deeper queries about things I’m more expert in generated superficial or incomplete answers. Direct queries asking ChatGPT what sources it used to generate its responses were not answered and the so-called “hallucinations'“ it had generating fictitious references were disturbing.
As an artist I was amazed at DALL-E’s ability to create an image based on a text prompt, fascinating to observe how it can readily combine disparate objects, and fun to see how initial creations morph based on changes to initial text prompt or requesting a specific style like Impressionism. However, I didn’t really think the images generated were mine or represented my artistic expression and I wondered about legalities associated with use of the image.
Underlying Data Set
I began to wonder about the underlying data set used to generate AI responses. Where did that data come from and how reliable is it? In computer science, there is a saying “garbage in, garbage out”. If AI is based on flawed internet data then the responses it generates may be wrong, inaccurate, or biased. It seems to me the sources and quality of the underlying data set used to train the AI are of paramount importance. I spent some time digging in to this and came up with some answers which I provide below. But details about the data are undisclosed. This lack of transparency makes open AI less open and leads to speculation and uncertainty.
The research article “Language Models are Few-Shot Learners” provides a good summary of ChatGPT’s underlying data and articles like “ChatGPT — Show me the Data Sources”, “OpenAI GPT-3: Everything You Need to Know”, and “Inside the secret list of websites that make AI like ChatGPT sound smart” provide additional context and analysis. ChatGPT builds its data model from several different sources of data scraped from the web (CommonCrawl, WebText2, Books1, Books2, Wikipedia). The multiple sources of data are used to enhance quality. It is interesting to learn that during training, datasets are not sampled in proportion to their size. Datasets viewed as higher-quality are sampled more frequently. The CommonCrawl and Books2 datasets are sampled less than once during training but Wikipedia is sampled over 3 times indicating a higher quality value associated with Wikipedia. It is fascinating to learn that an openly licensed (CC BY-SA) source like Wikipedia is so important to AI.
“Wikipedia’s value in the age of generative AI” notes:
“The process of freely creating knowledge, of sharing it, and refining it over time, in public and with the help of hundreds of thousands of volunteers, has for 20 years fundamentally shaped Wikipedia and the many other Wikimedia projects. Wikipedia contains trustworthy, reliably sourced knowledge because it is created, debated, and curated by people. It’s also grounded in an open, noncommercial model, which means that Wikipedia is free to access and for sharing, and it always will be. And in an internet flooded with machine generated content, this means that Wikipedia becomes even more valuable.”
“In the past six months, the public has been introduced to dozens of LLMs, trained on vast data sets that can read, summarize, and generate text. Wikipedia is one of the largest open corpuses of information on the internet, with versions in over 300 languages. To date, every LLM is trained on Wikipedia content, and it is almost always the largest source of training data in their data sets.”
“Wikipedia’s Moment of Truth” has this to say:
“While estimates of its influence can vary, Wikipedia is probably the most important single source in the training of A.I. models.”
“Wikipedia going forward will forever be super valuable, because it’s one of the largest well-curated data sets out there. There is generally a link between the quality of data a model trains on and the accuracy and coherence of its responses.”
That said the use of open licensed resources for training AI is contentious.
The origins of the tension begin back in 2014 and are well documented by OpenFuture. As they note “by then there were almost 400 million CC-licensed photos on Flickr. That year researchers from Yahoo Labs, Lawrence Livermore National Laboratory, Snapchat and In-Q-Tel used a quarter of all these photos to create YFCC100M, a dataset of 100 million photographs of people created for computer vision applications. This dataset remains one of the most significant examples of openly licensed content reusing. Because of the massive scale and the productive nature of the dataset, it became one of the foundations for computer vision research and industry built on top of it. The YFCC100M dataset set a precedent, followed by many other datasets. Many of them became standardized tools used for training facial recognition AI technologies.” OpenFuture goes on to further note in their “AI Commons” report this case, "raised fundamental questions about the challenges that open licensing faces today, related to privacy, exploitation of the commons at massive scales of use, or dealing with unexpected and unintended uses of works that are openly licensed." These fundamental questions are driving a rethink of open.
Legal or Illegal
I’ve always wondered about scraping data from the web. Is that legal? There are contradicting views with judges in some cases saying it is legal in others illegal. However, assuming web scraping is legal (it certainly is a common practice) AI developers assert that their use of the content and data from web scraping such as the Common Crawl dataset that underlies ChatGPT, and LAION, the image data set used by DALL-E, are legal under fair use.
The Creative Commons article “Fair Use: Training Generative AI” provides a good overview of the considerations and lays out the case for fair use.
Fair use involves four factors:
The purpose and character of the use, including whether such use is of commercial nature or is for nonprofit educational purposes
Courts typically focus on whether the use is “transformative.” That is, whether it adds new expression or meaning to the original, or whether it merely copies from the original.
The nature of the copyrighted work
Using material from primarily factual works is more likely to be fair than using purely fictional works.
The amount and substantiality of the portion used in relation to the copyrighted work as a whole
Borrowing small bits of material from an original work is more likely to be considered fair use than borrowing large portions. However, even a small taking may weigh against fair use in some situations if it constitutes the “heart” of the work.
The effect of the use upon the potential market for, or value of, the copyrighted work
I think the fair use argument is pretty sound when it comes to transformative purpose and use, primarily factual use, and amount and substantiality. But the fourth factor, impact on market, is more contentious.
In addition to Common Crawl and Wikipedia, ChatGPT uses the WebText2, Books1, and Books2 data sets. The article “AI Training Datasets: the Books1+Books2 that Big AI eats for breakfast” contains a good summary of those data sets. Of particular interest is just how opaque these data sets are. In the context of “open” it’s fair to say these data sets are not very open. Also of great interest to me were the identified two flaws to the data sets:
no knowledge of current events whatsoever. An AI formed by static datasets is effectively a “knowledge time capsule” that gets stale with age.
no sensory data to give it practical knowledge of the real world. An analogy might be a human in a coma, whose only functioning organs are its eyes and its brain, and who has the text of every book, magazine and newspaper ever printed sequentially scrolled in front of its eyes, with no way to view anything else, ever. No pictures, no movies, no fingers, no touch, no sound, no music, no taste, no talking, no smell, no walking or talking or eating or…. Just… 100% reading. And that’s it.
Despite the assertion that these data sets are provided under fair use, it is contentious. There are lots of ongoing debates and lawsuits. For example “Authors Accuse OpenAI of Using Pirate Sites to Train ChatGPT” and “Authors file lawsuit against OpenAI alleging using pirated content for training ChatGPT” describe a class action lawsuit against OpenAI, accusing ChatGPT’s parent company of copyright infringement and violating the Digital Millennium Copyright Act (DMCA). According to the authors, ChatGPT was partly trained on their copyrighted works, without permission. The authors never gave OpenAI permission to use their works, yet ChatGPT can provide accurate summaries of their writings something only possible if ChatGPT was trained on Plaintiffs’ copyrighted works. It also suggests these books were accessed through pirate websites something it appears other AI developers may also be doing.
It is fair use factor four “the effect of the use upon the potential market’ that is perhaps most hotly contested.
“Artists Are Suing Artificial Intelligence Companies and the Lawsuit Could Upend Legal Precedents Around Art” is a good summary of some of the issues associated with image generating AI.
“Record label battles with generative AI carry lessons for news industry” reflects some of the battles related to music.
Loss of income, jobs and livelihood seem highly pertinent to “effect of the use upon the potential market”.
RAIL Licenses
In November of 2022 I had the good fortune to attend an AI Commons Roundtable at the Internet Archive in San Francisco hosted by Open Future. One thing really stands out for me from that round table. Historically “open”, in the context of education and culture, has relied on use of Creative Commons licenses which are based on copyright law. All of the AI legally contested cases referenced above present their legal arguments using intellectual property (IP) and copyright law. But at the roundtable we discussed whether IP and copyright are really the best legal means for managing AI. Are Creative Commons licenses relevant in the context of AI? Will Creative Commons licenses evolve in response to the fundamental questions and challenges open faces today?
I was fascinated to learn about the RAIL initiative and their licenses. Responsible AI Licenses (RAIL) empower developers to restrict the use of their AI technology in order to prevent irresponsible and harmful applications. These licenses include behavioural-use clauses which grant permissions for specific use-cases and/or restrict certain use-cases.
The basic premise is that open is not synonymous with good. Open may lower the barriers to harmful uses. In order to mitigate harm, including safety and security concerns, open licenses need to evolve from simply being “open” to being “open” and “ responsible”.
Here is an example of a Responsible AI End User License Agreement. Of particular interest is the part 4 of the license describing “Conduct and Prohibitions”. The list of prohibitions is extensive and addresses many of the concerns that have been raised about AI. I recommend you read the entire list but here is a small sampling of the kinds of prohibitions specified.
The introductory Conduct and Prohibitions section includes agreeing not to:
“stalk,” harass, threaten, or invade privacy
impersonate any person or entity
collect, store, or use personal data
along with lots of other requirements
Under Surveillance, among other things, it prohibits use of AI to:
Detect or infer aspects and/or features of an identity any person, such as name, family name, address, gender, sexual orientation, race, religion, age, location (at any geographical level), skin color, society or political affiliations, employment status and/or employment history, and health and medical conditions.
A Computer Generated Mediated prohibition is agreement not to:
Synthesize and/or modify audio-realistic and/or video-realistic representations (indistinguishable from photo/video recordings) of people and events, without including a caption, watermark, and/or metadata file
Some Health Care prohibitions are to not to use AI to:
Predict the likelihood that any person will request to file an insurance claim or
Diagnose a medical condition without human oversight
A Criminal prohibition includes agreeing not to:
Predict the likelihood, of any person, being a criminal, based on the person’s facial attributes or another person’s facial attributes
These are but a sample, the full text of RAIL licenses covers even more territory when it comes to ethical and responsible use. It is interesting to reflect on whether the requirements and prohibitions specified in RAIL licenses are comprehensive enough to curb all ethical concerns. Personally, I think it would be helpful to specify not just what you can’t do in the form of“prohibitions” but what you encouraged to do in the form of “permissions”.
See “The Growth Of Responsible AI Licensing” for a summary on adoption and use of RAIL licenses.
Behavioural-use clauses are based more on contract law than copyright.
When I worked at Creative Commons (CC) I advocated for an addition to all Creative Commons licenses that would enable creators to express their intent. My belief was that expression of intent and downstream fulfillment of that intent would lead to more and better sharing. While expression of intent never came to be included in CC licenses I am finding it fascinating that intent is a significant aspect of AI. There are two aspects to intent in AI. Intent of the creators of AI as expressed in the licenses under which they make their tools available (eg. RAIL Licenses) and the ability of AI to understand user intent. See “User Intent: How AI Search Delivers What Users Want” for a bit more on user intent. I think the recognition of intent as being an essential aspect of AI is an tremendously important. And I applaud the development of behaviour-use clauses in licenses that aim to limit exploitation.
In the context of open education I published a similar set of behaviour recommendations in “Commons Strategy for Successful and Sustainable Open Education”. My aim was to go beyond mere legal compliance to define a set of behaviours associated with being a good actor in open education. I defined detrimental behaviour and constructive behaviours. Example constructive were situated along a continuum going from Positive First Step to Optimal. Providing behavioural guidance makes it clear that open entails going beyond mere legal compliance to responsibly stewarding an open commons using norms and practices.
In “On the emerging landscape of open AI”Alek Tarkowski notes, “Open vs responsible” is now a big topic in AI circles. But it also raises questions for the broader space of open sharing and for companies and organizations built on open frameworks. And it signals an urgent need to revisit open licensing frameworks. Anna Mazgal calls this “a singularity point for open licensing” and also argues for a review of open licenses from a fundamental rights perspective.” I’ll be attending the upcoming Creative Commons Global Summit in Mexico city and look forward to participating, with others from around the world, in reimagining open licensing frameworks.
Making Layers of AI Open
When considering AI from an open perspective the underlying data set is just one consideration. I’ve been looking at diagrams of the AI technology stack with the aim of getting a handle on what the layers of AI architecture are and which layers are, or could be, open.
This generative AI tech stack diagram by a16z provides a good starting point:

At the bottom is a layer of special high performance compute hardware with accelerator chips optimized for AI model training and inference. This layer is high cost such that only big high tech players can afford to build it out.
Above that are Cloud Platforms making the compute hardware available to AI developers in a cloud deployment model. Cloud platforms provide tools and interfaces for data scientists, IT professionals and, non-technical business staff to create AI-based applications. Providing access to Compute Hardware through the cloud makes AI development less costly and more feasible for smaller enterprises.
The middle layer is comprised of models close sourced but exposed via API’s to developers and models open sourced, hosted on model hubs like Hugging Face and Replicate.
The models are used to create end user facing applications with and without proprietary models.
I like this generative AI stack diagram but it is missing an important element I’ve already discussed - Data. AI models derive their value from the data they’re trained on. So, there’s a need to factor in data.
Here’s an AI diagram from the AI Infrastructure Alliance showing data and model training in more detail:

It is interesting to see the data is not used in raw form but goes through a series of processes to enhance the quality of the data - clean, validate, transform, label. These steps involve humans who must sift through the data to identify and prevent objectionable materials appearing in output. From an open perspective I wonder whether this cleaned data is considered proprietary to the AI developer? If Wikipedia data is “cleaned” or “ transformed” surely there is a requirement to share that back via the open license Wikipedia uses - CC BY-SA? Perhaps all cleaned data, scraped from the web, should be openly licensed so others don’t have to go through the same cleaning process?
Models
I like the way the diagram shows the AI Machine Learning workflow associated with training a model based on source data. Machine learning (ML) is an AI technique that uses mathematical algorithms to create predictive models. An algorithm is used to parse data fields and to "learn" from that data by using patterns found within it to generate models. Those models are then used to make informed predictions or decisions about new data with considerable accuracy. The predictive models are validated against known data, measured by performance metrics selected for specific use cases, and then adjusted as needed. This process of learning and validation is called training and produces a trained model or models.
This diagram from LeewayHertz modifies the generative AI stack diagram presented earlier to show different types of trained AI models.

General AI models aim to replicate human-like thinking and decision-making processes. They are intended to be versatile and adaptable, able to perform a wide range of tasks and learn from experience.
Foundation models are a recent development, in which AI models are developed from algorithms designed to optimize for generality and versatility of output. Those models are often trained on a broad range of data sources and large amounts of data to accomplish a wide range of downstream tasks, including some for which they were not specifically developed and trained. Those systems can be unimodal or multimodal, trained through various methods such as supervised learning or reinforced learning. AI systems with specific intended purpose or general purpose AI systems can be an implementation of a foundation model, which means that each foundation model can be reused in countless downstream AI or general purpose AI systems. These models hold growing importance to many downstream applications and systems.” Foundation Models can handle a broad range of outputs across categories such as text, images, videos, speech, code and games.
These General and Foundation models are designed to be user-friendly and open-source, representing a starting point for specific AI applications. The open source character of these models is important. It takes a lot of effort to create a general or foundation model. Making that available to others who can then add a small amount of custom data to the general or foundation model enables widespread use.
The sophistication and performance of a general AI model is judged by how many parameters it has. A model’s parameters are the number of factors it considers when generating output. The main difference between ChatGPT-2 and ChatGPT-3 is the size of the model. ChatGPT-2 is a smaller model with 1.5 billion parameters, while ChatGPT-3 is much larger with 175 billion parameters. This means that ChatGPT-3 is able to process more data and learn more complex relationships between words. It is interesting to learn that the conventional view of AI models being as smart as they are because of the vast amount of data on the internet today is false. It turns out that a smaller amount of high quality data with a larger model (expressed in parameters), is a better way to go.
However, general or foundation models aren’t naturally suited to all applications. For tasks requiring fully referenced high levels of accuracy specific models may be better.
I learned more about foundation models from IBM’s '“What are Foundation Models?” and Red Hats “Building a Foundation for AI Models”.
As noted in the Red Hat video foundation models aren’t usually deployed in an AI application. Instead they go through further training using specific data resulting in the creation of a Specific AI model, also known as domain-specific model, designed to excel in specific tasks. These models are trained on highly specific and relevant data, allowing them to perform with greater nuance and precision than general or foundation AI models. Most specific AI models are currently proprietary but as AI continues to evolve, specialized models are expected to become more open-sourced and available to a broader range of users.
Hyperlocal AI models go even further building even more capability from detailed data. They can achieve high levels of accuracy and specificity in their outputs generating outputs with exceptional precision. HyperLocal models are designed to be specialists in their fields, enabling them to produce highly customized and accurate outputs aligned to specific needs.
AI models are key elements of the AI world. From an open perspective a “model” is separate and distinct from the underlying source data, and and above layers of source code that make up the AI application. The model itself is licenseable.
The Turing Way Machine Learning Model Licenses provides a good overview of the licenses used for training models including the use of RAIL licenses. As they note, “While many ML models may utilise open software licensing (for example MIT, Apache 2.0), there are a number of ML model-specific licenses that may be developed for a specific model (for example OPT-175B license, BigScience BLOOM RAIL v1.0 License), company (for example Microsoft Data Use Agreement for Open AI Model Development), or series of models (for example BigScience OpenRAIL-M (Responsible AI License)).
From an open perspective it is interesting to see this growing list of ML licenses. It is particularly fascinating to see these new licenses go beyond the terms of prior open licenses generating new licensing options. However, it does raise a question around proliferation of licenses, their compatibility, and the extent to which they hinder or enable AI.
Complicating the picture are the big AI players who are creating their own special licenses. “Meta launches Llama 2, a source-available AI model that allows commercial applications" describes Meta’s approach and some of their considerations:
“Meta launched Llama 2, a source-available AI model that allows commercial applications" notes the recent Meta announcement of Llama 2, a new source-available family of AI language models notable for its commercial license, which means the models can be integrated into commercial products, unlike its predecessor.
In February, Meta released the precursor of Llama 2, LLaMA, as source-available with a non-commercial license. Officially only available to academics with certain credentials, someone soon leaked LLaMA's weights (files containing the parameter values of the trained neural networks) to torrent sites, and they spread widely in the AI community. Soon, fine-tuned variations of LLaMA, such as Alpaca, sprang up, providing the seed of a fast-growing underground LLM development scene.
Llama 2 brings this activity more fully out into the open with its allowance for commercial use, although potential licensees with "greater than 700 million monthly active users in the preceding calendar month" must request special permission from Meta to use it, potentially precluding its free use by giants the size of Amazon or Google.
While open AI models with weights available have proven popular with hobbyists and people seeking uncensored chatbots, they have also proven controversial. Meta is notable for standing alone among the tech giants in supporting major openly-licensed and weights-available foundation models, while those in the closed-source corner include OpenAI, Microsoft, and Google.
Critics say that open source AI models carry potential risks, such as misuse in synthetic biology or in generating spam or disinformation. It's easy to imagine Llama 2 filling some of these roles, although such uses violate Meta's terms of service. Currently, if someone performs restricted acts with OpenAI's ChatGPT API, access can be revoked. But with the open approach, once the weights are released, there is no taking them back.
However, proponents of an open approach to AI often argue that openly-available AI models encourage transparency (in terms of the training data used to make them), foster economic competition (not limiting the technology to giant companies), encourage free speech (no censorship), and democratize access to AI (without paywall restrictions).
Perhaps getting ahead of potential criticism for its release, Meta also published a short "Statement of Support for Meta's Open Approach to Today's AI" that reads, "We support an open innovation approach to AI. Responsible and open innovation gives us all a stake in the AI development process, bringing visibility, scrutiny and trust to these technologies. Opening today’s Llama models will let everyone benefit from this technology."
The proliferation of licenses and the desire to have them address responsible and ethical issues suggests a need for different licensing bodies to dialogue and coordinate definitions and uses of open licenses across all layers of the AI tech stack.
“Generative AI and large language models: background and contexts” provides a thorough review of large language models including open source ones and the range of issues around them. Of additional interest are the descriptions of specialist models and the potential for content generators/owners such as publishers to become the unexpected winners as LLMs become more widely used.
“The value of dense, verified information resources increases as they provide training and validation resources for LLMs in contrast to the vast uncurated heterogeneous training data scraped from the web. The potential of scientific publishers, Nature and others, whose content is currently mostly paywalled and isolated from training sets is highlighted along with the largest current domain-specific model BloombergGPT created from a combination of Bloomberg's deep historical reservoir of financial data ad more general publicly available resources.”
It goes on to say:
“The position of Hugging Face is very interesting. It has emerged as a central player in terms of providing a platform for open models, transformers and other components. At the same time it has innovated around the use of models, itself and with partners, and has supported important work on awareness, policy and governance.
It will also be interesting to see how strong the non-commercial presence is. There are many research-oriented specialist models. Will a community of research or public interest form around particular providers or infrastructure?”
The AI Infrastructure Alliance has an AI Infrastructure Landscape map showing machine learning operations and training activities along with which platforms handle various workflows and workloads including those who are open sourced.
As noted with the specific and hyperlocal model descriptions one of the central developments in AI is iterating models where pre-trained models are trained or fine-tuned a little bit more on a much smaller dataset. This AI is Eating the World diagram shows three ways for iterating a model:

The user data in this diagram is of particular interest as can be seen in this diagram where we see customization of models occurring through two methods, one involving ingestion of proprietary data and the other involving customizatin through use of user data including prompts and AI generations:

From an open perspective there are several key factors to consider with this representation of iterating models.
First Users own their own data. Use of that data by the AI developer must be based on users having openly licensed that data or allowing the developer to use their data based on Terms of Use typically agreed to as a precondition of using the AI application.
Zoom’s attempt to redefine their Terms of Service to authorize use of user data to improve their AI shows repercussions of trying to force this on users. See “Zoom's Updated Terms of Service Permit Training AI on User Content Without Opt-Out”
A second factor is related to a fascinating aspect of AI generation - Who owns AI generated output?
As Paul Keller notes in “AI, The Commons, And The Limits Of Copyright” "we need to move away from the analytical framework provided by copyright, which is based on the ownership of individual works, and recognize that what generative ML models use are not individual works for their individual properties but rather collections of works of unimaginable size: state-of-the-art image generators are trained on billions of individual works, and text generators are regularly trained on more than 100 billion tokens." It’s crucially important to understand that there is a fundamental difference between reproducing content and generating content. Generative AI doesn’t reproduce content from source data it generates new content.
The US Copyright Office provides general guidance on the copyrightability of generative AI outputs through the Compendium of U.S. Copyright Office Practices. The Compendium’s language rejects as uncopyrightable all works produced by a machine or mere mechanical process that operates randomly or automatically without any creative input or intervention from a human author. As noted in “Who Ultimately Owns Content Generated By ChatGPT And Other AI Platforms?” “For a work to enjoy copyright protection under current U.S. law, the work must be the result of original and creative authorship by a human author. Absent human creative input, a work is not entitled to copyright protection. As a result, the U.S. Copyright Office will not register a work that was created by an autonomous artificial intelligence tool.” The article “AI-generated art can be copyrighted, say US officials – with a catch” provides additional nuance to this position. If AI outputs are not subject to copyright then it begs the question, “Are AI outputs in the public domain?”
There are increasing discussions about whether prompts should themselves be openly licensed. Underlying that is what permissions users of AI technologies like ChatGPT are giving the company (OpenAI) who owns that technology. We’ve already discussed OpenAI use of data or content you may have produced in their underlying data set. However, what about your questions, prompts and other interactions associated with use of ChatGPT as shown in the model iteration diagram above. Can OpenAI use your inputs to improve their model? “How your data is used to improve model performance” makes it clear that “ChatGPT, improves by further training on the conversations people have with it, unless you choose to disable training.” Kudos to OpenAI for providing an option to opt out, “you can switch off training in ChatGPT settings (under Data Controls) to turn off training for any conversations created while training is disabled or you can submit this form. Once you opt out, new conversations will not be used to train our models.” The default mining of end user data is a continuation of large platform tactics. You are knowingly or unknowingly contributing to AI through data scraped from the web and through your interactions with AI tools. From an open perspective this default setting ought to be that end user data ownership and privacy requires opt in, not opt out, agreement around use of data in model iteration and improvement efforts.
I find it particularly interesting to see the increasing focus on prompts used in AI systems rather than the content generated. David Wiley writes a couple of interesting blog posts (see here and here) exploring “what if, in the future, educators didn’t write textbooks at all? What if, instead, we only wrote structured collections of highly crafted prompts? Instead of reading a static textbook in a linear fashion, the learner would use the prompts to interact with a large language model.” David goes on to note that “yes, you could openly license your generative textbook (collection of prompts). But the fundamental role of OER changes dramatically in future scenarios where the majority of the learning material a student engages with is generated on the fly by an LLM, and was never eligible for copyright protection in the first place.”
Applications
Many AI platforms make their foundation and other models available to other developers via API’s. This enables others to build unique applications on top of foundation models or customize a foundation model with their own data to perform a specific task.
End user applications at the top of the AI tech stack automate and deliver a variety of task-based capabilities ranging from image generation, to general writing, tutoring / advising, and code generation.
There are a wide range of diagrams showing the AI application landscape. The landscape is rapidly changing but here is a simple diagram from Sequoia showing model and application layers across multiple fields.
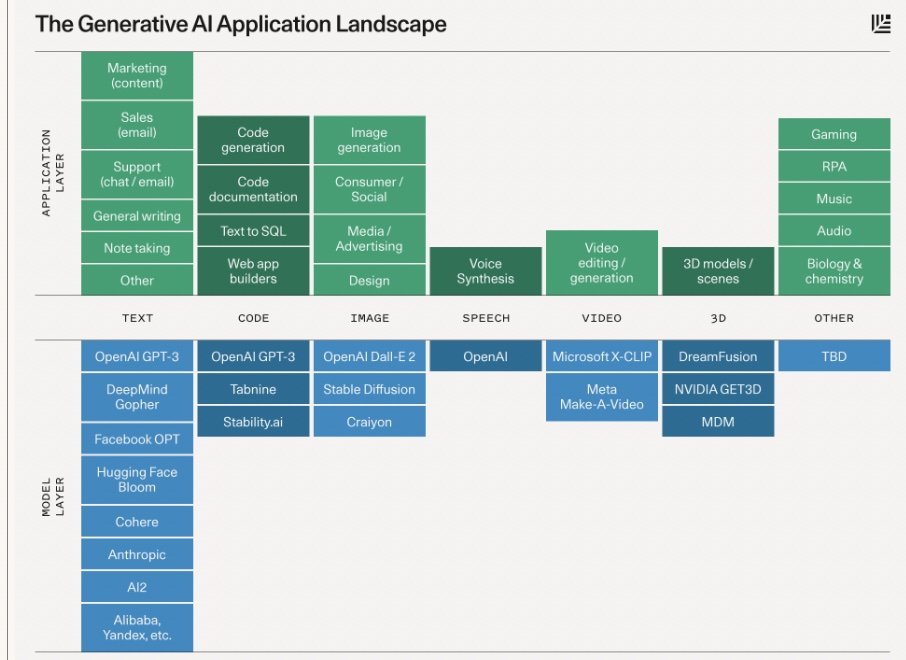
From an open perspective the apps and applications that perform these tasks are open licenseable. The blog post "From Rail To Open Rail: Topologies of Rail Licenses" explores real-world questions around (i) the nature of artifacts being licensed - i.e. the data, source, model, binaries/executables, (ii) what could constitute derivative works for each, (iii) whether the artifact’s license enables permissive downstream distribution of such artifact and any derivative versions of it (e.g. with commercial terms of any kind). This provides essential background to the use of RAIL licenses. Example RAIL licenses are provided for AI models (AIPubs OpenRAIL-M), AI source code (AIPubs OpenRAIL-S), and responsible AI end user licenses (RAIL-A License).
OpenAI's "Introducing ChatGPT and Whisper APIs" blog post describes how they open license code and models and “Whispers of A.I.’s Modular Future” chronicles one persons use of Whisper a model capable of transcribing speech in more than ninety languages.
This diagram from Deedy maps applications in the AI language sector against the AI stack. Deedy’s diagram places the stack horizontally along the x axis rather than vertically as in previous diagrams. Doing so gives a kind of sense of progression and the complex inter-relationships across layers of the stack.

Application Programming Interfaces (APIs)
This diagram also shows a new layer to the tech stack called “Framework / API”. AI developers are hosting models and development tools in the cloud and making it possible for others to use these models and development tools via API’s.
An API, or application programming interface, is a system that allows two or more two or more software programs to interact and understand each other without communication problems. You could think of it as a sort of intermediary that helps one software program share information with another one. An open API is based on an open standard, which specifies the mechanism which queries the API and interprets its responses. A closed API refers to technology that can only be used by the developer or the company that created it. An open API is different in that any developer has free access to it via the Internet. This allows organizations to integrate AI into the software tools they use every day gaining access to certain features of a software program that would be difficult to access without taking the time to develop a large amount of code.
Companies, like OpenAI, develop their own apps and make them available via an API so that other companies can also use them. This type of arrangement offers a win-win situation for both companies. The developing company generates revenue from other companies that use their app, and the company using the app gets greater efficiency or functionality.
The “Gradient of Generative AI Release: Methods and Considerations” does a great job of describing six levels of access to generative AI system models: fully closed; gradual or staged access; hosted access; cloud-based or API access; downloadable access; and fully open. Each level, from fully closed to fully open, can be viewed as an option along a gradient.
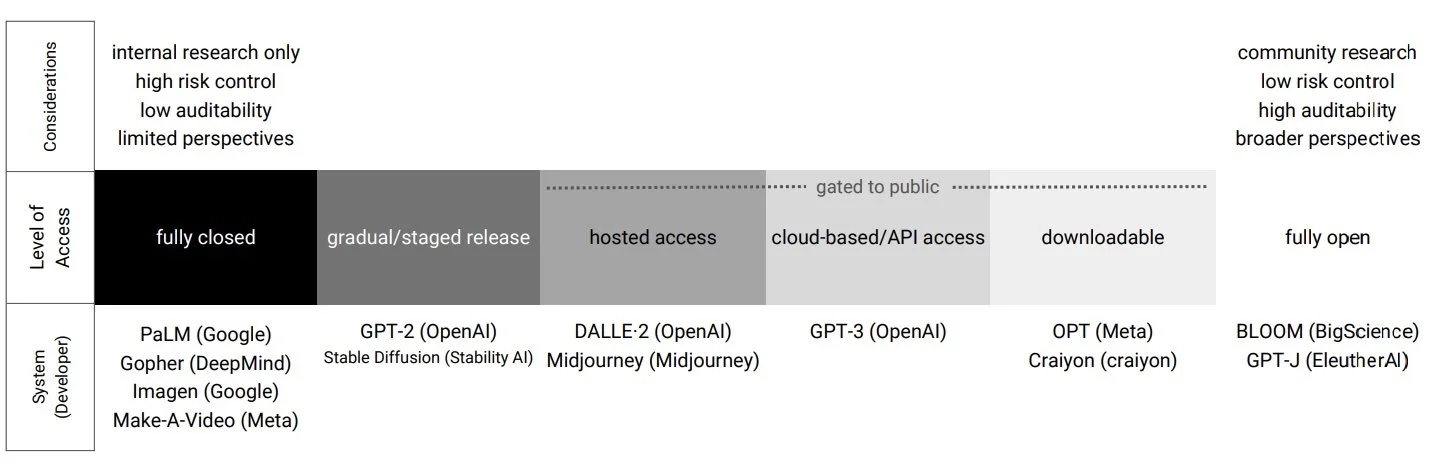
The paper outlines key considerations across this gradient taking note of the tradeoffs, especially around the tension between concentrating power and safety. It also shows trends in generative system release over time, noting closedness among large companies for powerful systems and openness among smaller organizations founded with the intent to be open. It is unclear at this time whether movements towards openness will pressure historically closed organizations to adjust their release strategies.
It’s been super helpful for me to see these different representations of the AI tech stack as a means to understanding the layers that make up AI and the extent to which they are open. It is clear that Open source in AI is very well established. As "The AI renaissance and why Open Source matters" says:
“Sharing knowledge and sharing code has always been a key driver for innovation in Artificial Intelligence. Researchers have gathered together since AI was established as a field to develop and advance novel techniques, from Natural Language Processing to Artificial Neural Networks, from Machine Learning to Deep Learning. The Open Source community has played a key role in advancing AI and bringing it to solve real-world problems. …”
However, "The AI renaissance and why Open Source matters" goes on to say:
"The world of AI is at an important crossroads. There are two paths forward: one where highly regulated proprietary code, models, and datasets are going to prevail, or one where Open Source dominates. One path will lead to a stronghold of AI by a few large corporations where end-users will have limited privacy and control, while the other will democratize AI, allowing anyone to study, adapt, contribute back, innovate, as well as build businesses on top of these foundations with full control and respect for privacy."
Open Across the AI Tech Stack Layers
While open is already integral to AI, nowhere did I find a diagram representing all the ways open is playing out across the different layers in the AI tech stack. In the absence of such a diagram I created my own, expanding the stack to show the API layer along with user interactions and generative AI output. An open perspective of open licensing considerations and questions is provided to the right of each stack layer.

Learning
I’m interested in AI in the context of open writ large. But a great deal of my career has focused on open in the context of education. I’m super impressed with the effort in academia to identify ways to use AI such as:
and many more including the role of open practices:
But what about the pedagogical ways in which AI is being trained. What are the pedagogies being used to develop artificial intelligence? To what extent is AI using contemporary learning theories and pedagogical approaches? Is AI automating poor pedagogical practices? When compared with human teachers and contemporary pedagogy is AI better?
Machine learning (ML), Deep learning, Large Language Learning Models (LLM), and other such terms pervade the AI literature. The “Difference Between Artificial Intelligence vs Machine Learning vs Deep Learning” provides a good overview. AI learning heavily relies on math, engineering and behaviourist models of learning. This underlying approach to learning lacks much of what we know in terms of contemporary pedagogy and limits the usefulness of AI in terms of engaging learners intellectually, physically, culturally, emotionally and socially. Compared to human teachers AI is, currently, very limited.
From the perspective of open the field of open education has much to offer including:
Open Educational Resources
Open Pedagogies
Open Access
Open Science and
Open Data
It will be interesting to see whether AI advances in terms of using more contemporary pedagogies in the underlying learning process used to train AI and in the ways it engages those using it.
Ethics
Part of what makes AI interesting, and contentious, are questions that are less legal and more ethical. Here is a sample of the many ethical concerns being expressed:
Is AI the greatest art heist in history?
"AI art generators are trained on enormous datasets, containing millions upon millions of copyrighted images, harvested without their creator’s knowledge, let alone compensation or consent. This is effectively the greatest art heist in history. Perpetrated by respectable-seeming corporate entities backed by Silicon Valley venture capital. It’s daylight robbery." Restrict AI Illustration from Publishing: An Open Letter
Is AI the appropriation of the “sum total of human knowledge”?
“Are we "witnessing the wealthiest companies in history (Microsoft, Apple, Google, Meta, Amazon …) unilaterally seizing the sum total of human knowledge that exists in digital, scrapeable form and walling it off inside proprietary products, many of which will take direct aim at the humans whose lifetime of labor trained the machines without giving permission or consent." AI machines aren’t ‘hallucinating’. But their makers are, Naomi Klein
Can AI solve the United Nations’ Sustainable Development Goals (SDGs)?
"We have less than 10 years to solve the United Nations’ Sustainable Development Goals (SDGs). AI holds great promise by capitalizing on the unprecedented quantities of data now being generated on sentiment behaviour, human health, commerce, communications, migration and more. The goal of AI for Good is to identify practical applications of AI to advance the United Nations Sustainable Development Goals and scale those solutions for global impact. It’s the leading action-oriented, global & inclusive United Nations platform on AI. AI for Good is organized by ITU in partnership with 40 UN Sister Agencies and co-convened with Switzerland." AI For Good
Will AI be marshalled to benefit humanity, other species and our shared home?, or Is AI built to maximize the extraction of wealth and profit?
“Will AI be "marshalled to benefit humanity, other species and our shared home?", or Is AI "built to maximize the extraction of wealth and profit – from both humans and the natural world" making it "more likely to become a fearsome tool of further dispossession and despoilation." AI machines aren’t ‘hallucinating’. But their makers are.” AI machines aren’t ‘hallucinating’. But their makers are, Naomi Klein
Will AI reproduce real world biases and discrimination fueling divisions and threatening fundamental human rights and freedoms?
"AI technology brings major benefits in many areas, but without the ethical guardrails, it risks reproducing real world biases and discrimination, fueling divisions and threatening fundamental human rights and freedoms." Message from Gabriela Ramos Assistant Director-General, Social and Human Sciences, UNESCO in Recommendation on the Ethics of Artificial Intelligence
Will AI develop rapidly and exponentially such that it surpasses human intelligence?
“The technological singularity is a hypothetical future event in which technological progress becomes so rapid and exponential that it surpasses human intelligence, resulting in a future in which machines can create and improve upon their own designs faster than humans can. This could lead to a point where machines are able to design and build even more advanced machines, leading to a runaway effect of ever-increasing intelligence and eventually resulting in a future in which humans are unable to understand or control the technology they have created. Some proponents of the singularity argue that it is inevitable, while others believe that it can be prevented through careful regulation of AI development.” AI For Anyone - Technological Singularity
Should private corporations be allowed to run uncontrolled AI experiments on the entire population without any guardrails or safety nets?
“The question we should be asking about artificial intelligence – and every other new technology – is whether private corporations be allowed to run uncontrolled experiments on the entire population without any guardrails or safety nets. Should it be legal for corporations to release products to the masses before demonstrating that those products are safe?” There Is Only One Question That Matters with AI
To these I might add:
Is it fair that the citizens who have generated the data necessary to train models have no input on how their data is used?
What are the repercussions of AI use leading to misinformed or unjustified actions?
Will AI propagate harmful and historically dominant perspectives?
Will AI further concentrate economic or cultural power?
Will AI have a social impact on employment, work quality and exploited labor?
What is the potential overall effect of AI on society?
As “AI Creating 'Art' Is An Ethical And Copyright Nightmare” notes AI “has been fun for casual users and interesting for tech enthusiasts, sure, but it has also created an ethical and copyright black hole, where everyone from artists to lawyers to engineers has very strong opinions on what this all means, for their jobs and for the nature of art itself.”
In “Common Ethical Challenges in AI” the Council of Europe shares a map of the concerns from their perspective:
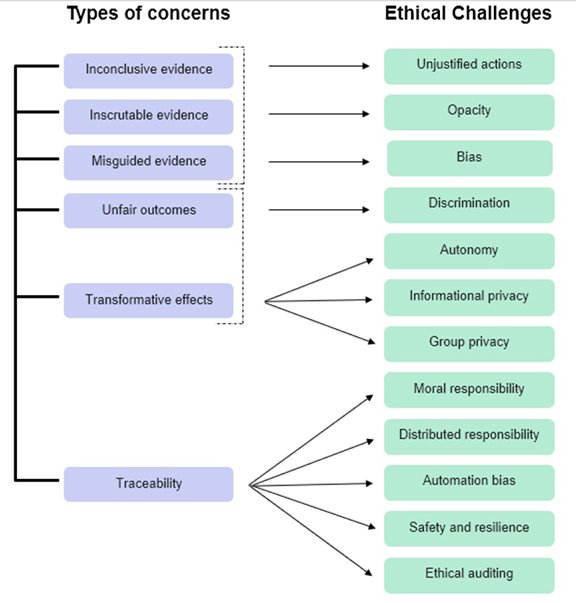
The article "Legal and Ethical Consideration in Artificial Intelligence in Healthcare: Who Takes Responsibility?" identifies four major ethical issues: (1) informed consent to use data, (2) safety and transparency, (3) algorithmic fairness and biases, and (4) data privacy.
UNESCO has published a “Recommendation on the Ethics of Artificial Intelligence” and recently announced a partnership between UNESCO and the EU to speed up the implementation of ethical rules.
Another UNESCO initiative, specific to education, generated the publication "AI and education: Guidance for policy-makers". I really like this as a great overview for policy makers on how AI affects education including promising examples, challenges associated with use, and approaches to policy. I admire the work Wayne Holmes is doing in this field and look forward to the outputs of his work with the Council of Europe developing regulation dealing with the application and use of AI systems within educational contexts.
There seems to be a consensus, even among AI developers, that thoughtful rules and guardrails are required to maximize AI’s potential for good and minimize the potential harms. However, at this point it seems that the way these responsible and ethical questions are going to be answered is through court cases and regulation.
Given the importance of open across all aspects of AI, I think the open movement should be more involved and proactive in advocating for openness too and shaping what regulation should look like.
AI Regulation
In some ways the emergence and evolution of AI seems to be following the same pattern as previous digital platforms. "AI makes rules for the metaverse even more important" describes it this way:
“In Act One, visionary innovators imagine what wonders digital technology can deliver and then bring them to life. The hype and hustle surrounding the metaverse recycles the “move fast and break things” mantra of the early internet. The focus last time was on what can be built rather than consideration of its consequences—should we expect anything different this time?
Act Two was the refinement of the technology’s application. By marrying computer science with behavioral science, such as casino psychology research, the platform companies were able to design applications to maximize their monetary potential. Today’s reprise moves beyond psychological science to embrace neurological science. One commentator has called out the “Three M’s of the Metaverse” —monitor users, manipulate users, and monetize users.
The unfinished Act Three features governments trying to keep pace with the tech companies racing ahead to establish their own behavioral rules. In the U.S., policymakers have stumbled around trying to determine what actions (if any) to take. Across the Atlantic, the European Union and the United Kingdom have moved forward to establish new rules for the internet we know today.
The challenge society now faces is determining whether there will be a stage manager for the new activities; not a director that dictates, but a supervisor that coordinates what is needed for the performance and its effect on the audience. Will the metaverse companies put their own stage management in place for the metaverse just like they did for their internet platforms? Or will the governments that were slow on the uptake in the early generation internet see the vast new developments of the metaverse as the trigger to assert themselves?”
AI needs a different approach. AI regulations, rules and norms ought to encourage use of open as a means of establishing ethical and responsible values, ensuring transparency, creating public good, stimulating AI innovation, mitigating risk, and generating new business models.
In "Advocating for Open Models in AI Oversight: Stability AI's Letter to the United States Senate" CEO Emad Mostaque says:
“These technologies will be the backbone of our digital economy, and it is essential that the public can scrutinize their development. Open models and open datasets will help to improve safety through transparency, foster competition, and ensure the United States retains strategic leadership in critical AI capabilities. Grassroots innovation is America’s greatest asset, and open models will help to put these tools in the hands of workers and firms across the economy.”
Machine Learning Street Talk has some great resources on AI including video clips and analysis of testimony at the US Senate hearings on AI oversight. In this clip Sam Altman, CEO of OpenAI, says :
“I think it’s important that any new approach, any new law, does not stop the innovation from happening with smaller companies, open source, researchers that are doing work at a smaller scale. Thats a wonderful part of this ecosystem, … and we don’t want to slow that down.”
Open source is already part of the AI ecosystem and is integral to many of the ethical and safety aims. However I’ve yet to see anything that proactively and clearly articulates the role of open across the AI stack and opens role in AI regulation, rules and norms.
The use of artificial intelligence in the EU will be regulated by the AI Act, the world’s first comprehensive AI law, at the time of this writing still in draft. This Regulation lays down a uniform legal framework for the development, the placing on the market and putting into service, and the use of artificial intelligence. Here is a good short summary of the intent of this regulation along with accompanying remarks from an open perspective.
“The parliamentary priority is to make sure AI systems are safe, transparent, traceable, non-discriminatory and environmentally friendly. “
Openness is a key means of ensuring AI Act priorities are met, especially as it relates to transparency, traceability and non-discrimination. The practice of open makes resources, whether they be source code or other digital media, freely open to others to view, use, modify and redistribute. It does so in ways that do not discriminate against any individual or group of people, meaning they must be truly accessible by anyone.
“The EU AI Act has different rules for different risk levels including:
1. Unacceptable Risk AI systems that are considered a threat to people will be banned.
This includes AI systems such as:
Cognitive behavioural manipulation of people or specific vulnerable groups: for example voice-activated toys that encourage dangerous behaviour in children
Social scoring: classifying people based on behaviour, socio-economic status or personal characteristics
Real-time and remote biometric identification systems, such as facial recognition
2. All High Risk AI systems that negatively affect safety or fundamental rights will be assessed before being put on the market and also throughout their lifecycle.
High risk AI systems will be divided into two categories:
1) AI systems that are used in products falling under the EU’s product safety legislation. This includes toys, aviation, cars, medical devices and lifts.
2) AI systems falling into eight specific areas that will have to be registered in an EU database:
Biometric identification and categorisation of natural persons
Management and operation of critical infrastructure
Education and vocational training
Employment, worker management and access to self-employment
Access to and enjoyment of essential private services and public services and benefits
Law enforcement
Migration, asylum and border control management
Assistance in legal interpretation and application of the law.”
I anticipate adoption of these risk categories will have a somewhat chilling affect on AI. There will be a lot of attention paid to the definition of each risk category and what is included in each. The high risk category is very broad and the requirements extensive, including registration, stringent reviews, and quality / risk management. The fines for non-compliance are large.
My field is education so it is interesting to see education and training designated High Risk. AI is already in use in the education sector for a wide range of purposes, some of which, such as plagiarism detection and academic online testing surveillance are highly controversial. The AI Act suggests these will be banned or at the very least deemed high risk.
“Generative AI, like ChatGPT, would have to comply with transparency requirements such as:
Disclosing that the content was generated by AI
Designing the model to prevent it from generating illegal content
Publishing summaries of copyrighted data used for training”
Here again is a regulation statement calling for openness and transparency. It might be helpful to offer guidance on what open tools and licenses fullfill these requirements.
“3. Limited risk AI systems will have to comply with minimal transparency requirements that would allow users to make informed decisions. After interacting with the applications, the user can then decide whether they want to continue using it. Users should be made aware when they are interacting with AI. This includes AI systems that generate or manipulate image, audio or video content, for example deepfakes.”
Recent amendments to the AI act, as documented in this Draft Compromise Amendments, take an even more restrictive approach by extending regulations to AI foundation models. All foundation models are categorized as High Risk. It is not clear why foundation models are high risk but specific or hyperlocal models are not. The repercussions of this may result in AI development being focused more on highly tailored or specific models rather than foundation ones.
The Draft Compromise Amendments acknowledge the important role open source is already playing in the AI landscape and seeks to incentivize further open source efforts noting the following exemptions:
“(12a) Software and data that are openly shared and where users can freely access, use, modify and redistribute them or modified versions thereof, can contribute to research and innovation in the market. Research by the European Commission also shows that free and open-source software can contribute between €65 billion to €95 billion to the European Union’s GDP and that it can provide significant growth opportunities for the European economy. Users are allowed to run, copy, distribute, study, change and improve software and data, including models by way of free and open-source licences. To foster the development and deployment of AI, especially by SMEs, start-ups, academic research but also by individuals, this Regulation should not apply to such free and open-source AI components except to the extent that they are placed on the market or put into service by a provider as part of a high-risk AI system or of an AI system that falls under Title II or IV of this Regulation.
(12b) Neither the collaborative development of free and open-source AI components nor making them available on open repositories should constitute a placing on the market or putting into service. A commercial activity, within the understanding of making available on the market, might however be characterised by charging a price, with the exception of transactions between micro enterprises, for a free and open-source AI component but also by charging a price for technical support services, by providing a software platform through which the provider monetises other services, or by the use of personal data for reasons other than exclusively for improving the security, compatibility or interoperability of the software.
(12c) The developers of free and open-source AI components should not be mandated under this Regulation to comply with requirements targeting the AI value chain and, in particular, not towards the provider that has used that free and open-source AI component. Developers of free and open-source AI components should however be encouraged to implement widely adopted documentation practices, such as model and data cards, as a way to accelerate information sharing along the AI value chain, allowing the promotion of trustworthy AI systems in the EU.
However, as noted in “Undermining the Foundation of Open Source AI?” there are concerns about the limited scope of the exemption including exclusion of open source foundation models. In addition to exemptions it would be useful to consider and make explicit the way open can be used to fulfill AI Act requirements.
While the EU Act is currently the most advanced in terms of documented regulation, albeit still draft, there are other countries engaged in a similar consideration of AI regulations. The US Senate hearings on AI oversight considered a variety of possibilities including:
The creation of an AI Constitution that establishes values ethics and responsible AI
The need to define ethics, values and responsible AI
Whether a regulating agency (think something similar to Food and Drug Administration) needs to be established
Need for an International Governing Body with authority to regulate in a way that is fair for all entities
Whether AI should be a “licensed” industry? Should government “license” AI much like other industry sectors and professions are licensed? Or should there just be controls on the AI platform and users?
To what extent AI should be a tested and audited industry
The use of something akin to“nutritional labels” as a means of identifying what is in AI systems and models along with additional documentation on their capabilities and areas of inaccuracy
Liability associated with AI
Competitive national interests
AI research
Regulating AI not based on the EU risk categories but rather on being above a certain level of computing or with certain capabilities
How to ensure a thriving AI ecosystem
and many more ideas
Open Across the AI Ecosystem
Open is already a significant driving force across all layers of the AI technology stack. But there is not yet any overarching effort to fully acknowledge its role across the broader AI ecosystem along with proactive suggestions for how to sustain, strengthen and expand on it. In an effort to fill that gap I offer the following Open Across the AI Ecosystem diagram and recommendations.
I’ve placed the AI Tech Stack Layers on the centre of the diagram. From the left AI Research and Development feeds in to all the AI Tech Stack Layers. From the right AI Ethics, Values and Legal including Open and Responsible Licenses, Regulation (national and global), and Community Self Governance feed in. On the far right I’ve added in all important AI Human factors such as Open Networks and Communities, End Users and Public Good.
Open Recommendations Across the AI Ecosystem
I’m keen to see the open community take a more proactive stance around influencing how AI is playing out. Toward that end I offer the following open recommendations across the AI ecosystem. Recommendations are grouped specific to each element of the Ecosystem diagram. I expect there are many more recommendations that could/should be added.
AI Research & Development
Already existing open practices including Open Access, Open Data, and Open Science should be default norms and practices for AI research and development.
Publicly funded AI research and development should include requirements for open
AI Tech Stack Layers
Compute Hardware & Cloud Platform
It is worth considering whether governments should invest in AI Compute Hardware and offer an AI Cloud Platform as open infrastructure to ensure public utility, support of research, and small to medium enterprise innovation. Being dependent on a few large tech providers seems ill-advised and risky. Such a move aligns well with recent statements on Democratic Digital Infrastructure and Invest in Open efforts to get open infrastructure funded as a public utility.
Article 53, Measures in Support of Innovation, of the EU AI Act talks about the creation of AI Regulatory Sandboxes that provide a controlled environment facilitating the development, testing and validation of innovative AI systems for a limited time before their placement on the market or putting into service pursuant to a specific plan. This seems like a tentative step toward open infrastructure. The open digital public infrastructure intent ought to be strengthened and emphasized.
Source Data & Enhanced Data
Existing court cases will clarify whether source data scraped from the web can be used legally based on fair use.
AI relies on the commons. More commons building is needed. AI needs to not just exploit existing commons but contribute to building more.
Creators want to know when their content is being used to train AI. AI developers have a responsibility to inform creators. Allowing creators to opt out is being trialed by AI developers. A more responsible approach is for creators to opt in.
Creator credit may be explicitly required.
Creator compensation may need to be negotiated. See “Comment Submission Pursuant to Request for Comments on Intellectual Property Protection for Artificial Intelligence Innovation” for an example. Owners of structured data sets may charge for AI ingestion.
Consider a social contract requiring any commercial deployment of generative AI systems trained on large amounts of publicly available content to pay a levy. As noted in AI, The Commons, And The Limits Of Copyright “The proceeds of such a levy system should then support the digital commons or contribute to other efforts that benefit humanity, for example, by paying into a global climate adaptation fund. Such a system would ensure that commercial actors who benefit disproportionately from access to the “sum of human knowledge in digital, scrapable form” can only do so under the condition that they also contribute back to the commons.”
It seems crucial from an ethical, responsible and public confidence perspective to require open publishing of what source data went into a model. The nutrition label concept seems self-evident and ought to be simple enough to comply with but specificity of detail and legality issues make this a hot topic requiring attention.
When openly licensed source data such as Wikipedia is cleaned, validated and transformed it ought to be shared back under the same CC BY-SA license.
Models
Responsible open licenses be the preferred means for licensing models
FAIR standards should be used for managing artificial intelligence models. See: “Argonne scientists promote FAIR standards for managing artificial intelligence models”
Each model should have accompanying documentation describing source data, its size, how it was trained, how it was tested, how it behaves, and what its capabilities and limitations are. These requirements ought to be more formally spelled out along with the requirement for this documentation to be openly licensed.
Foundation models should be open source
Application Programming Interfaces
Enhancing models using API data is by default prohibited.
Apps and Applications
The benefits of open such as transparency, fostering innovation and economic activity, and democratizing access address AI ethical and value issues. Open source apps and applications ought to be encouraged and incentivized.
End User Interactions
Enhancing models using end user data is by default prohibited.
End users ought to have the option of allowing their data to be used to enhance open foundational models or open digital AI infrastructures rather than corporate proprietary AI
Generative Outputs
Works produced by a machine or mere mechanical process that operates randomly or automatically without any creative input or intervention from a human author are uncopyrightable. Generative AI content by default is in the public domain
Consider ways of identifying generated works so they are labelled to indicate it is AI generated.
AI Ethics, Values, Legal
Open & Responsible Licenses
The proliferation of licenses and the desire to have them address responsible and ethical issues suggests a need for different licensing bodies to dialogue and coordinate definitions and uses of open licenses across all layers of the AI tech stack.
Open licenses need to transition from being based on Intellectual Property and Copyright law to a broader range of legal means (including contract law) that define use and behaviour
Open licensing needs to broaden from a focus on individual ownership to include joint ownership and collective works
Regulation (National & Global)
Ethics, values and norms, including those based on open, need to be built in up front and across the AI ecosystem. Create an AI Constitution that establishes values ethics and responsible AI.
Regulation should include the use of responsible open licenses as a means of ensuring ethics and values
Establish an AI International Governing Body that works toward ensuring national regulations don't conflict and are fair for all entities
Regulations around AI ought to consider differentiation based on a variety of factors including:
risks to public safety
open vs proprietary
compute power
AI capabilities
number of users
offered for commercial use or not
public good
The EU AI Act should support the use of open source and open science. See: Supporting Open Source And Open Science In The EU AI ACT and associated letter.
The widespread practice of using Terms of Use agreements requiring end users to click “I agree” to terms they’ve never read giving permission to platforms to access and use end user data needs to be stopped through regulation.
Community Self Governance
Open players across the AI ecosystem should come together proactively to define, coordinate and enhance the use of open norms and practices across the AI ecosystem
The community should help define acceptable norms inside, who and how they will be protected/enforced, and what are the responsibilities of the companies that profit are
Adopt an approach based on the principles of commons-based governance. See AI Is Already Out There. We Need Commons-Based Governance, Not a Moratorium
Open is an essential skill and practice in the AI ecosystem (and beyond). Continuing, enhancing and building out open skills and practices ought to be a shared goal along with a shared understanding of the values associated with doing so.
AI Human
Open Communities & Networks need to be supported. Community of practice efforts such as that supported by the Digital Public Goods Alliance (DPGA) and UNICEF provide essential advice and recommendations. See “Core Considerations for Exploring AI Systems as Digital Public Goods” I particularly appreciate the way this discussion paper adds a human layer to the AI Software Stack
End Users need to be given the opportunity to not only use AI but contribute to AI as a form of public good
A central objective should be not just safe, transparent, traceable, non-discriminatory and environmentally friendly AI but AI that generates public good. AI not only needs guard rails but it needs incentives to ensure open and public good as an outcome not just corporate profits
Generating this blog post has been a deep dive over an extended period of time. I acknowledge this is an unusually long ambitious blog post but AI is complex, opens role in it evolving, and my interest is in understanding the big picture. I have learned a huge amount in writing this post and I hope that, in reading it, you have too. My biggest hope in presenting AI from an open perspective is that a greater understanding of the importance of open will emerge and galvanize more efforts to enhance and strengthen it.
Discussion related to this post is taking place on Open Education Global’s discussion forum Connect. Welcome your voice there along with feedback and ideas: